DAN THAT IS A MOUTHFUL!
In another life I was an academic random internet person, deal with it and move on.
So a couple of members of the team have been pushing me to document the Local SEO Guide approach to SEO and a topic came up internally over the past few weeks that I think is a great example. I think the mental model we have for approaching SERPs and rankings is broken. Specifically, it’s causing people to misunderstand how to approach SEO as a discipline and it’s all our own fault for the push to make everything quickly understandable and non-complex. Complex things are complex, it’s okay. Just to be upfront, I’m not going to provide you a new heuristic in the context of this piece, I’m just here posing problems.
Background
We need to get some conceptual foundations built up before we can knock them down.
First, it’s important to understand two critical concepts for this post:
False Precision: Using implausibly precise statistics to give the appearance of truth and certainty, or using a negligible difference in data to draw incorrect inferences.
Cognitive Bias: A systematic error in thinking that occurs when people are processing and interpreting information in the world around them and affects the decisions and judgments that they make.
On our mental model of SERPs; I think it’s pretty non-controversial to say that most people in the SEO space have a heuristic of SERPs based on these 3 things:
Results are ordered by positions (1-10)
Result are incremented by units of 1
Results scale equally (1 and 2 are the same distance from each other as 3 and 4, 4 is 3 units away from position 1 etc)
This is so totally and completely wrong across all points:
Results are ordered by match to an information retrieval system (e.g. best match, and diverse matches etc). There are theoretically a lot of different “best answers” in the 10 blue links. Best news site, best commercial site, best recipe etc.
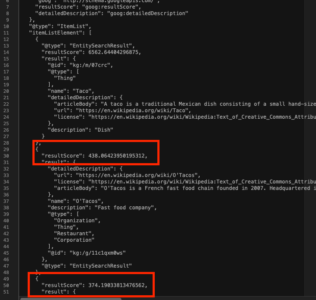
Results are ordered by however “apt” the web document is at answering the query. Not even close to some linear 1-10 ranking system. Below is a screenshot of the Knowledge Base Search API returns matches for “tacos” with the scores of the 2nd and 3rd results highlighted:
If you want to do a deep dive into this, Dr. Ricardo Baeza-Yates has you covered here in his 2020 RecSys Keynote on “Bias on Search and Recommender Systems”.
This logically follows from the previous point. Per the screenshot of Knowledge Base Search results for “tacos” we can see the distance between search results is not actually 1. The distance between position “2” and position “3”, highlighted in the screenshot above, is 64. This is going to be REALLY important later.
{kind=link}
Additional Important Knowledge
The internet and keywords are a long tail distribution model. Here is a background piece on how information retrieval experts think about how to address that in recommender systems.
{kind=link}
~18% of keyword searches every day are never before seen keywords searches.
Many SERPs are impossible to disambiguate. For example, “cake” has local, informational, baking and eCommerce sites that provide “apt” results for versions of “cake” all at once in the same SERP.
Implications
So I first started diving into all this when working with statisticians on our quantitative research around local search ranking factors around five years ago, and it has a lot of implications in regards to interpreting SERP results. The best example is when it comes to rank tracking.
There is an assumption made about how much closer position 5 is to position 1 than position 11 but this is totally and completely obfuscated by the visual layer of a SERP. As I illustrate with Google Knowledge Base API search, machines match terms/documents based on their own criteria which is explicitly not a 1-10 scale. With this in mind and knowing that large systems like search are long tail, that means that lots of “bad”, low scoring results, are still the “best” match for a query.
In these instances of the 18% of daily queries that are new instances every search result could be very close in rankability in position 1, separated by small differences. This means it could be just as easy to move from position 7 to position 1 for lots of queries as it is easy for them to move from position 12 to 1.
Using the example above, saying that positions 7-10 are meaningfully different from each other is like saying positions 1 & 2 in this example are meaningfully different from each other. It’s using a negligible difference in data to draw incorrect inferences, which is the textbook definition of false precision.
{kind=link}
To take it even further, the majority of page 1 results could be middling results to the query because it’s new and search engines have no idea how to rank it based on their systems that use user behavior etc to rank things. Since it’s a new query to them, lots of parts of their system won’t be able to work to the same degree of specificity as it would for a term like “tacos”. This means the distribution could be even more negligible between positions on a SERP.
Dan, how do you know this is how the distribution is?!?!?!?!
Random internet stranger, please do keep up. None of us know how the distribution of the rankability of items is done in any SERP, not even Googlers. All hypotheses about how Google’s orders search results are unable to be proven untrue (falsified) e.g. you can’t science any of this. That is literally my point.
Back to “tacos“; in high volume, deep knowledge queries like that, the best results that Google could return are likely incredibly good answers (per their systems) and barely differentiated in terms of the different SERP positions.
This means the top restaurant on page 2 for tacos is unlikely to be meaningfully worse than the ones on page 1 given a high inventory of documents to analyze and return. Thankfully I live in SoCal…. But that doesn’t mean that Google does.
Remember earlier when I did a Knowledge Graph API search to show how these things are scored? Well let’s check out two of my favorite words: “Taco Score”. If you want to play along at home go to this link and hit execute in the bottom right corner.
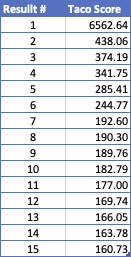
This below chart shows the “results score” for the top 15 results that the API returned for “tacos”:
Besides the fact that everything after the first result is playing catch up, the difference between positions 6 & 7 is the same as the difference between 7 & 15. Talk about insignificant differences that you should not use to draw any conclusions…
If you need a graph to better understand, check out this long tail distribution curve
{kind=link}
{kind=link}
Solutions
Alright Dan, you convinced me that our mental model of SERPs is hijacking our brains in negative ways and our false precision is leading us astray, BUT WHAT DO I DO ABOUT IT?
Well, I’m glad you asked, random internet stranger as I have a few concepts and tools that will hopefully help you move beyond this cognitive blocker.
Systems Theory
{kind=link}
In order to overcome false precision, I personally recommend adopting a “Systems Theory” approach, and checking out Thinking in Systems by Donella Meadows (old version available for free here).
This is important because systems theory basically says that complex systems like Google search are true blackboxes that not even the people working on the systems themselves know how they work. This is honestly just observable on face when Google’s systems stopped using rel=prev and rel=next and it took them a couple years to notice.
The people who work on Google Search do not know how it works in order to predict search outcomes, it’s too complex a system. So we should stop using all this false precision. It looks foolish IMHO, not clever.
{kind=link}
Embracing Uncertainty
Y’all, I hate to break this to you but search outcomes aren’t predictable in any way based on doing some SEO research and proposing a strategy and tactics as a result.
{kind=link}
We ascribe precise meaning to unknowable things in order to better help our fragile human brains cope with the anxiety/fear of the unknown. The unknown/uncertainty of these complex systems is baked into the cake. Just take into account the constant, crushing pace of Google algo updates. They are constantly working to change their systems in significant ways basically every month.
By the time you are done being able to do any real research to understand how much an update has changed how the system operates they have already changed it a couple more times. This is why update/algo chasing makes no sense to me. We work in an uncertain, unknowable, complex system and embracing that means abandoning false precision.
Thinking Fast/Thinking Slow
This is a concept of the mind/behavioral economics put forward by nobel prize winning economist Daniel Kahnamen.
{kind=link}
How this relates to issues of cognitive bias is that this bias often arises from “fast thinking” or System 1 thinking. I’m not going to dive too deep into the difference between these two or explain them. Instead here is Daniel Kahnamen explaining it himself as well as an explainer post here.
Just to illustrate how important I think this concept is to SEO as well as leadership and decision making; I ask people in interviews “What is your Superpower?” and one of the most incredible SEOs I have ever had the pleasure of working with (shout out Aimee Sanford!) answered “slow thinking” and that was that.
Takeaways
I honestly think SEO is pretty simple, and gets overly complicated by the fact that our discipline is just way over crowded with marketers marketing marketing. If people are talking about analyzing a core algorithm update outside a specific context and/or making sweeping statements about what and how Google is behaving, then you should know that that is full of false precision.
We can’t even meaningfully discuss the distance between individual search positions, let alone how internet scale systems work. If you internalize all of this false precision, it will lead to cognitive biases in your thinking that will impair your performance. You will do worse at SEO.
Now we just all need to tap into our slow thinking, overcome our cognitive bias, stop using false precision and develop a new mental model. Simple right?
The post SEO The LSG Way: Cognitive Bias and False Precision in our SERP Mental Model appeared first on Local SEO Guide.